We have been using Github since the start of the Data Science Campus as the primary home for both our private and public code. In this post, I talk a bit about how we are using Github and the Github API in our day-to-day project processes.
This post is not about project management, but more about the data which can be derived from, and ultimately used in the project management and planning process.
In the Data Science Campus, the focus of my work is usually outward, aimed at delivery of research, data products, tools and services. Looking inward, I am of course very much interested in the high level processes which guide and ultimately facilitate the progress of my work and of the team in which I belong.
We currently have many projects in various stages of development, ranging from ideas, proposals, live and completed projects. Our projects cover a wide spectrum, covering a range of Machine Learning and AI domains making use of a broad variety of data sources within an interdisciplinary, applied research environment. Our team has grown from a handful of Data Scientists, to a collective of 20. As such, it is a significant task to scale our existing delivery process and keep track of each idea, proposal and project.
High level view
As a data science team, we work on many projects in parallel. All of our projects live in Github, in private and public form. As such, it makes sense that our code and processes live in the same place.
In general, the life-cycle of each of our projects can be viewed as a kind of Finite State Machine, in the sense that a project can only ever be in one state at a time and state transitions are clearly defined and unambiguous.
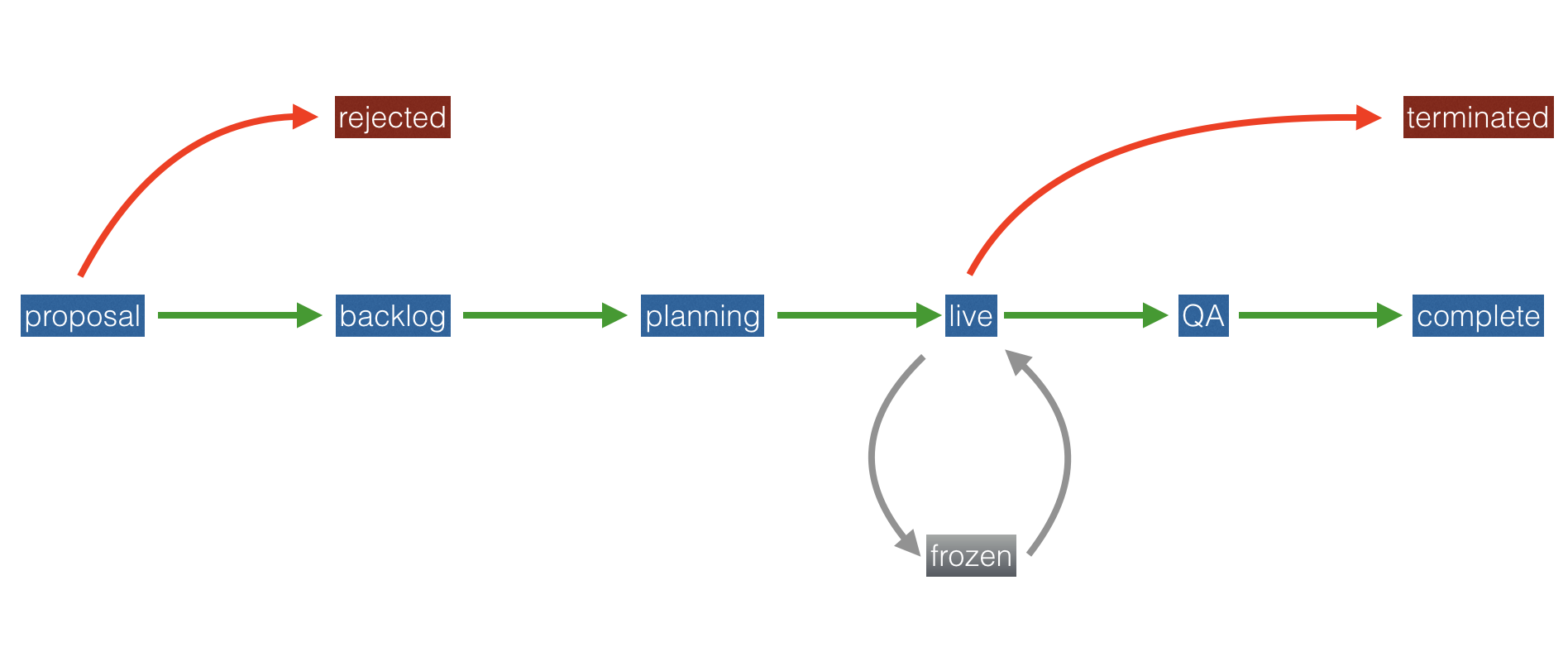
Each project starts life as a proposal and later progresses to backlog, planning, live, QA and finally, complete states. Our backlog is a priority queue (more on this in a later post), planning and live are early stage and mature projects respectively.
In practice, this project life-cycle maps to a list of projects in various stages.
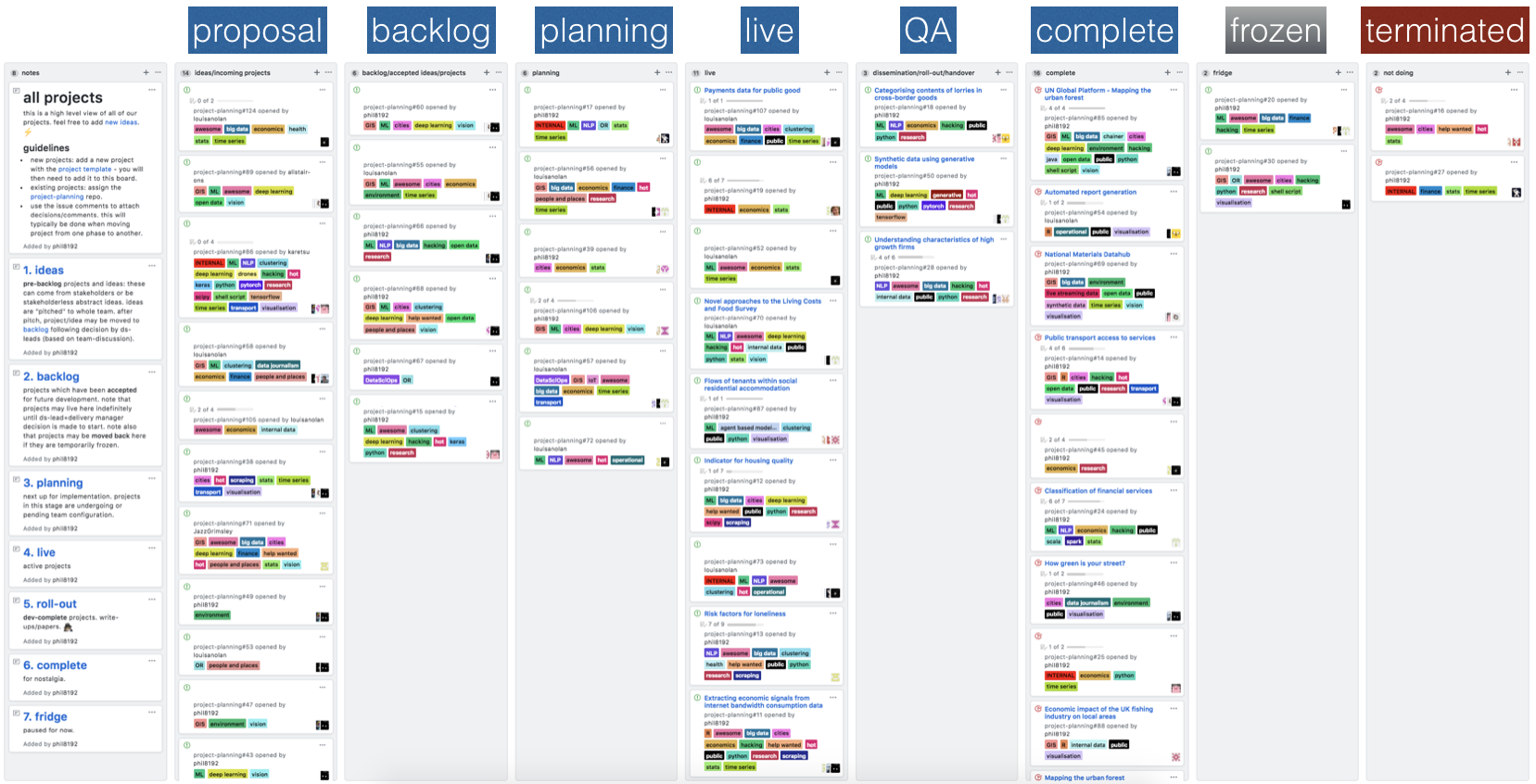
We have made use of Github’s project boards to keep track of each project. Each project is represented by a high-level Github issue and placed in a column corresponding to the project state.

The nice thing about Github issues is the labeling feature. We currently assign each project a set of labels corresponding to the general research strand (e.g., economics, urban analytics) and a “data science tech stack”.
The tech stack describes the techniques and technologies which are being used to deliver the work.
We can then filter the project board by technology type and research strand, which is very useful with a large number of active projects.
As an extension, we have started to introduce a taxonomy of labels, by using the colour code scheme: red for programming languages, blue for research areas, green for stakeholder etc.
For consistency between each project, we make use of the
custom issue template
functionality: The project list is associated with a repository with a custom
issue template added to .github/ISSUE_TEMPLATE. Our current template consists
of a project synopsis, team details, a description of the technical challenge
and list of code and other outputs.
Interacting with the Github API
Now the fun part.
The benefit of using Github issues as a way to hold our high level project life- cycle is that Github issues are exposed via the Issues REST API. This means that we can begin to automate some processes.
Document generation
The first process we have automated is the generation of different types of document which are shared between people outside of Github.

Since the project descriptions are specified using
Markdown, we can use
Pandoc to generate .docx, .html and .pdf outputs.
The main benefit of this is that there is a central source of information:
changes made to the initial markdown will be reflected across all document
types.
Assuming Github credentials stored in $HOME/.netrc:
machine api.github.com
login my_github_username
password my_github_developer_key
We can get a list of projects inside a state column (shown above) using the
column id as reference. In this example, 2872021 is the id of our Live
projects - this can be obtained from the Copy column link option inside the
ellipses at the top right hand side of each column.
Here I use curl and the excellent ./jq command-line JSON processor to extract the issue URL for all live projects:
curl -ns -H 'Accept: application/vnd.github.inertia-preview+json' \
-H 'Content-Type: application/json' \
-X GET 'https://api.github.com/projects/columns/2872021/cards' \
|jq -r '.[] .content_url'
Then, for a specific issue (project), can obtain a JSON representation containing the project team members, labels and embedded project description markdown:
curl -ns -H 'Accept: application/vnd.github.inertia-preview+json' \
-H 'Content-Type: application/json' \
-X GET 'https://api.github.com/repos/org_name/project_info/issues/$id \
> project.json
We can use JQ to extract the project meta info:
cat project.json \
|jq -r '"title: " + (.title |gsub(":|\/"; "-")),
"date: " + (.created_at |sub("T.*$"; "")),
"team: [" + ([.assignees[].login] |join(", ")) + "]",
"tags: [" + ([.labels[].name] |join(", ")) + "]",
"modified: " + (.updated_at |sub("T.*$"; ""))' \
> project.yaml
And associated markdown: cat project.json |jq -r '.body' > project.md.
Project portfolio
This blog is hosted using Github pages which uses Jekyll for static site generation. In addition to a blog, we have also created a public facing project portfolio which contains a complete, up-to-date view of all of our projects.

To create the portfolio, a set of scripts parse the project meta and markdown
data obtained via the Github issues API to create a project summary list and
individual pages for each project. There is also an option to download the
project information in .pdf or .docx format.
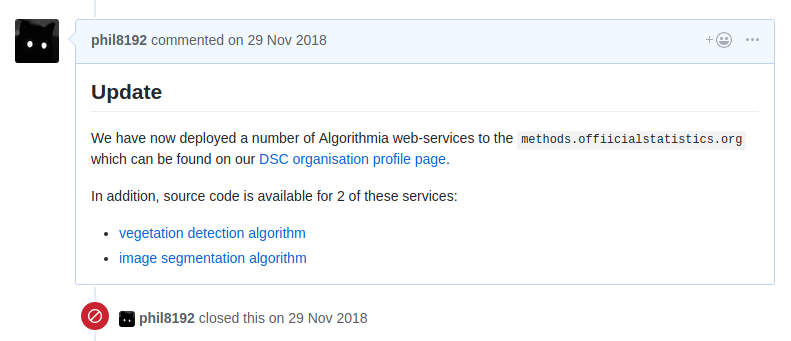
As an extra feature, the scripts will parse any Github issue comment which has
been prefixed with ## Update and output each in the form of a project log for
each of the projects. See
here
for example.
Project summary statistics
In addition to static website and document generation, we also output a matrix which we currently use to generate summary statistics for use in project planning.
The matrix makes use of the meta data obtained from the previous steps and currently looks like this:
| Title | State | Tech 1 | Tech 2 | .. | Tech N | Person 1 | Person 2 | .. | Person N |
|---|---|---|---|---|---|---|---|---|---|
| Project 1 | Backlog | 1 | 0 | 1 | 0 | 0 | 1 | ||
| Project 2 | Live | 1 | 1 | 1 | 1 | 1 | 0 | ||
| .. | .. | .. | .. | .. | .. | .. | .. | .. | .. |
| Project N | Complete | 0 | 1 | 0 | 0 | 1 | 0 |
So, for each project we have a machine readable set of attributes covering
project life-cycle state (factor), technology/data science stack and team
members (boolean). This basic information can be imported into R (for example)
x <- read.csv("summary.csv") and used to answer a surprising number of
questions such as:
How many projects is each person (currently) working on?
sort(colSums(x[x$state == 'Live' | x$state == 'Handover', 56:ncol(x)]), decreasing=T)
Who is currently not assigned to any upcoming project?
counts <- colSums(x[x$state == 'Planning', 56:ncol(x)])
sort(names(counts[counts == 0]))
What type of projects is a person working on and who are they working with?
counts <- colSums(x[x[, which(colnames(x) == 'phil8192')] &
(x$state == 'Live' |x$state == 'Handover'), 5:ncol(x)])
counts[counts > 0]
Closing thoughts
In this post, I’ve given a brief overview of how we make use of Github for high level project life-cycle tracking and how we use the issues API to pull project information to be included in our public facing project portfolio.
The main benefit of this approach is that we have a single source of information for our projects and use of the Github API allows us to automate a large part of our project processes.
In the next post, I’ll go a step further and use the project state matrix output above as input to a method to automatically prioritise incoming projects.