
Introduction
We, the Office for National Statistic (ONS) Data Science Campus, use GitHub for hosting private and public code. Private repositories are used for project management and developing code. Public repositories comprise developed and tested code made available for wider public use and development.
For internal use and to make consistent working processes easier, the Campus has created a private template repository - called skeletor. In this training post, the Campus shares some of its ways of working.
Text in code comments style is used for GitHub technical terminology, bold for Agile terminology, and green text for the Campus’ own terminology.
Project Portfolio
Project Lifecycle
The Campus adopts an active project lifecycle process, where a project is first pitched as an Idea to all data scientists. This Idea can come from a Campus member, from stakeholder engagement, or from a wider research proposal.
This proposed project is then taken to the Campus’ Project Board where a decision is made whether to take the project into a Discovery phase, or not. In a Discovery phase, the Campus aims to test the feasibility of the project, explore datasets, conduct an ethical review, and work with the stakeholders to create user stories. During this phase the Campus works in an Agile framework (i.e. sprints) to meet our objectives (i.e. milestones). Ideas that do not pass the criteria set by our Project Board are either kept for a finite time and revisited once the recommended changes have been implemented, or they are rejected outright. Ideas that pass the Project Board but there is insufficient resources, legal and/or data issues, are put into a Planning-backlog pile.
The findings of the Discovery phase are then taken back to the Project Board, whom decide whether to move the project into the Delivery phase. Again in this phase, the project is undertaken using an Agile manner. Campus data scientists work alongside the Campus’ development team to develop a tool for the stakeholders to be able to answer their research question(s). Ideas that do not pass the Discovery phase are marked as DNPD (Did Not Pass Discovery). Ideas that do pass the Project Board but there is insufficient resources, legal and/or data issues, are put into a Delivery-backlog pile.
The next stage is the Dissemination phase, where the tool is handed over to the stakeholder. Lastly, after successful deployment of the tool to the stakeholder, the project is marked as Complete.
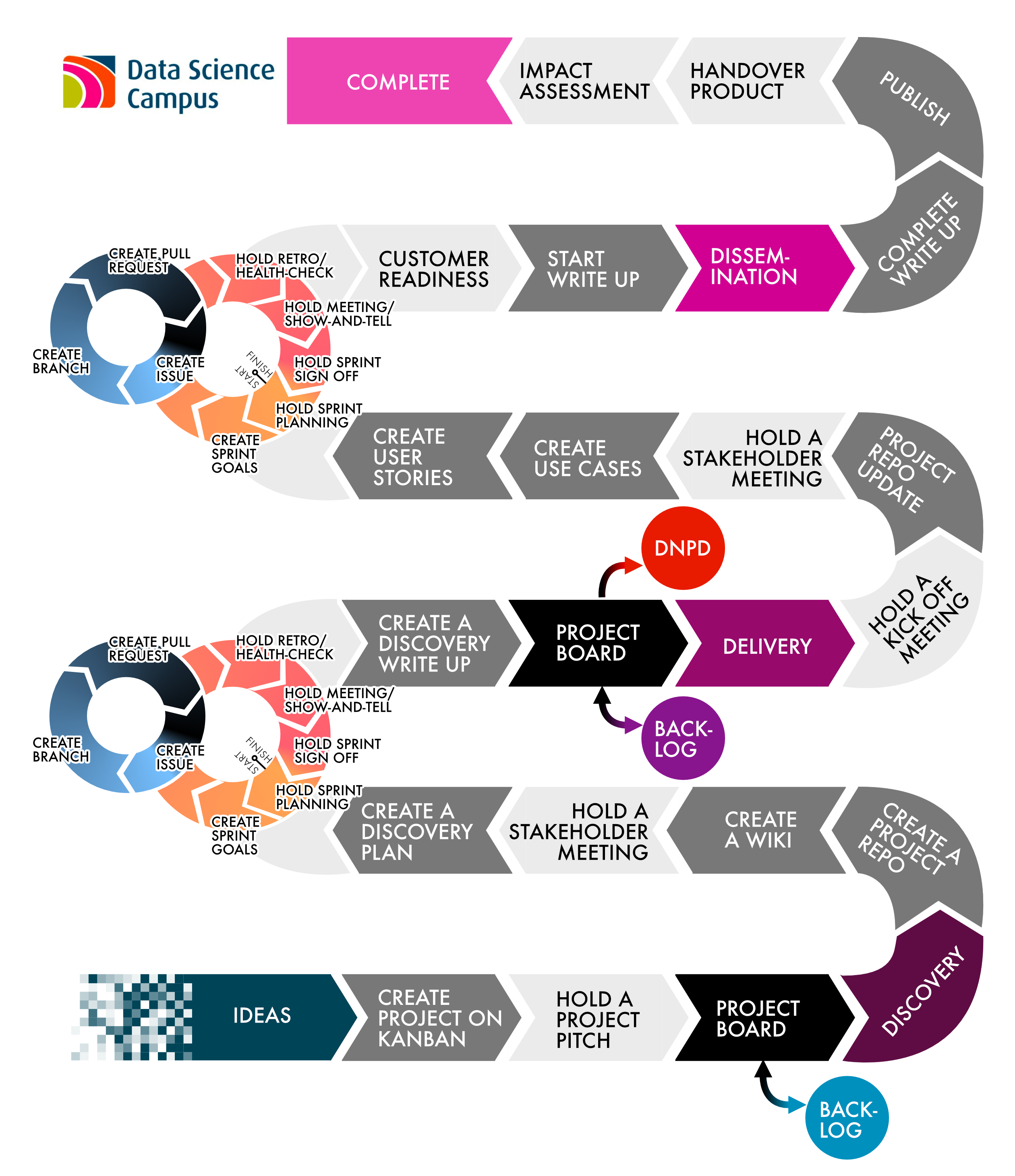 Image of the project lifecycle and pathway used by the Data Science Campus
Image of the project lifecycle and pathway used by the Data Science Campus
Project Portfolio Kanban Board
In order to observe how a project moves through the various phases, the Campus has setup a Project Portfolio Kanban board on GitHub, where each project is an Issue. Each issue is then assigned to a lifecycle phase (e.g. Idea) on the Kanban project portfolio board. Using an Issue allows the Campus’ delivery management team to tag assignees (those who will be working on the project), and labels (to describe the project). The Campus also used free text tag hooks that update the projects page when particular comments are made on the Issues.
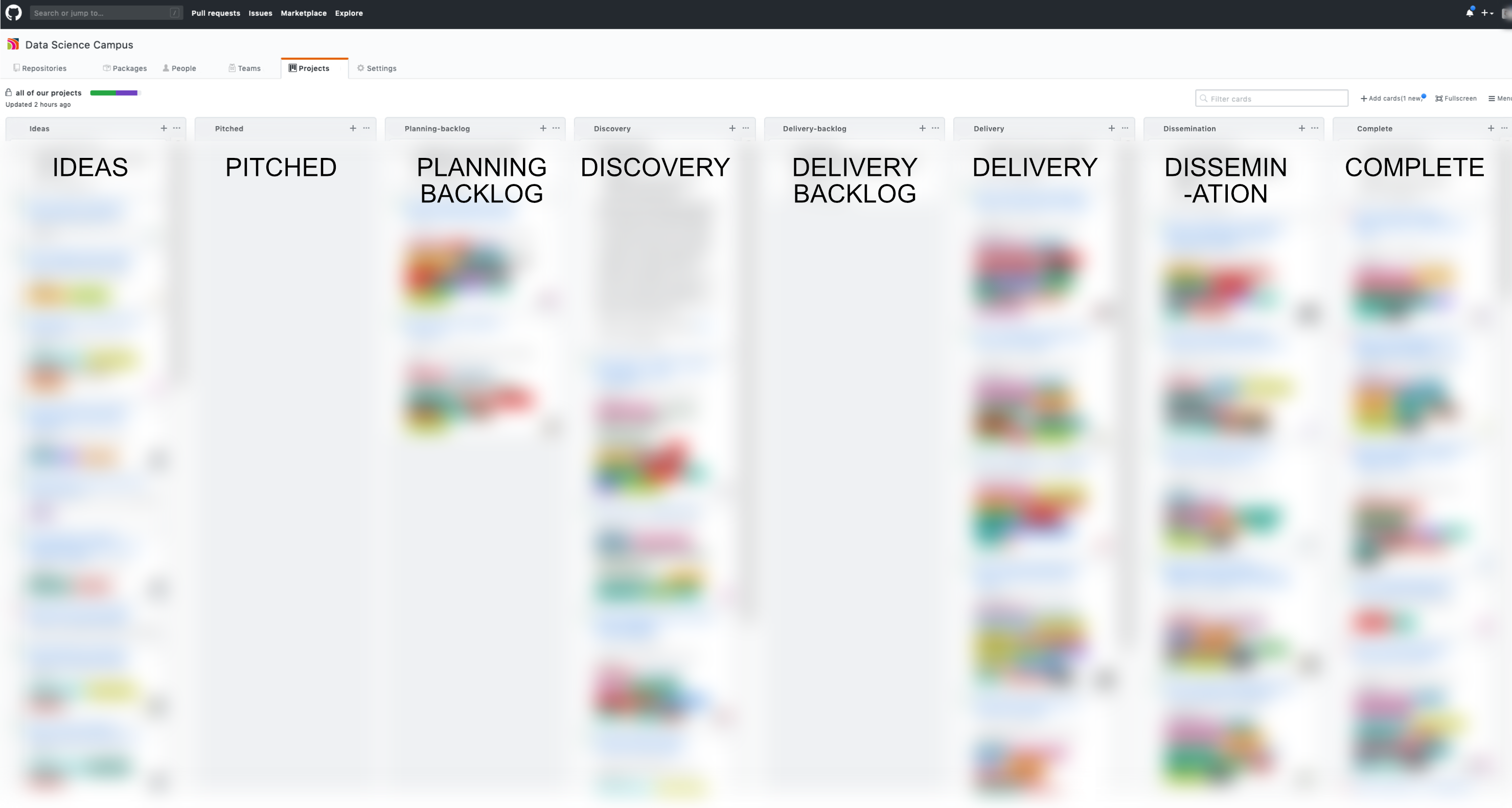 Image of the project Kanban portfolio board used by the Campus
Image of the project Kanban portfolio board used by the Campus
Key Performance Indicators
The Campus has developed a number of labels that help describe the project. These include the size of the project (small, medium, or large), who the stakeholder is (ONS, government, international, or other), what data is used (admin data, commercial data, open data, or survey data), what coding languages are used (e.g. Python, R, Scala), what data science techniques the project involves (e.g. NLP, Geospatial, Deep Learning) and how it aligns to the Campus’ internal strategic objectives and impact framework. There is also a blocker tag catergory, which helps the Campus identify projects that need extra resource, or have data issues etc.
The benefit of using these labels is that the Campus can use the GitHub API to pull down project status at regular intervals. This allows the Campus to analyse and report on Key Performance Indicators periodically. In the future, data such as how long the project was expected to take can be combined with the number of project personnel, actual time it took to complete the project, size of the project and the type of project, to help the Campus better estimate project forecasting.
Project Management and Collaborative Coding
Each project then has an associated GitHub repository (e.g. pyGrams), where coding and project management happens. All Campus project repositories start as private; depending on the nature of the work, they may then be made public.
Working in an Agile manner means the Campus uses sprints (set working timeframes), retrospectives (reflective meetings to understand what went well, or not so well), stand-ups (to let team members know what each other is working on), show and tells (to show other Campus members or stakeholders of progress or tool prototype) and hold regular meetings with the stakeholders (to revisit the objectives).
To use the GitHub repository in an Agile manner the Campus has created their own template (skeletor), and follows the GitFlow approach for coding. Below is a condensed version of this framework.
Project Management
Project Phase
Project phases are recorded as Projects in a specific GitHub code repository related to a specific project, where each phase (e.g. Discovery) is a separate Project. Projects are setup with an Automated Kanban with Reviews template so that there are some automated responses to actions like creating and close tasks (Issues).
Milestones
Milestones are used in GitHub to separate each delivery target for the project (also a milestone in Agile terminology). In a Discovery phase, the Campus has have certain distinct Milestones to reach the end of the phase, such as producing an ethical review, or delivering a code demo. In Delivery and Dissemination phases, the milestones are related to the need of the project to achieve the stakeholders requirements.
Note, if there are very high-level milestones, such as ‘Complete Data Engineering’ these should be split into sub-milestones instead. In this case, the high-level milestone can be recorded in the wiki (see below) and the sub-milestones should be recorded in Milestones.
Sprints
Sprints typically last two weeks. The Campus records sprints using labels where the label name is Sprint <num> <start_day>/<start_month> <end_day>/<end_month>, e.g. Sprint 1 25/11 9/12.
Tasks
Issues are used to record individual tasks. Tasks should be small, manageable and achievable. An Issue can be created during a sprint planning meeting, or during a sprint. An Issue should be assigned to one or more project workers, given a sprint label, assigned to a Milestone, and the Project phase (e.g. Discovery).
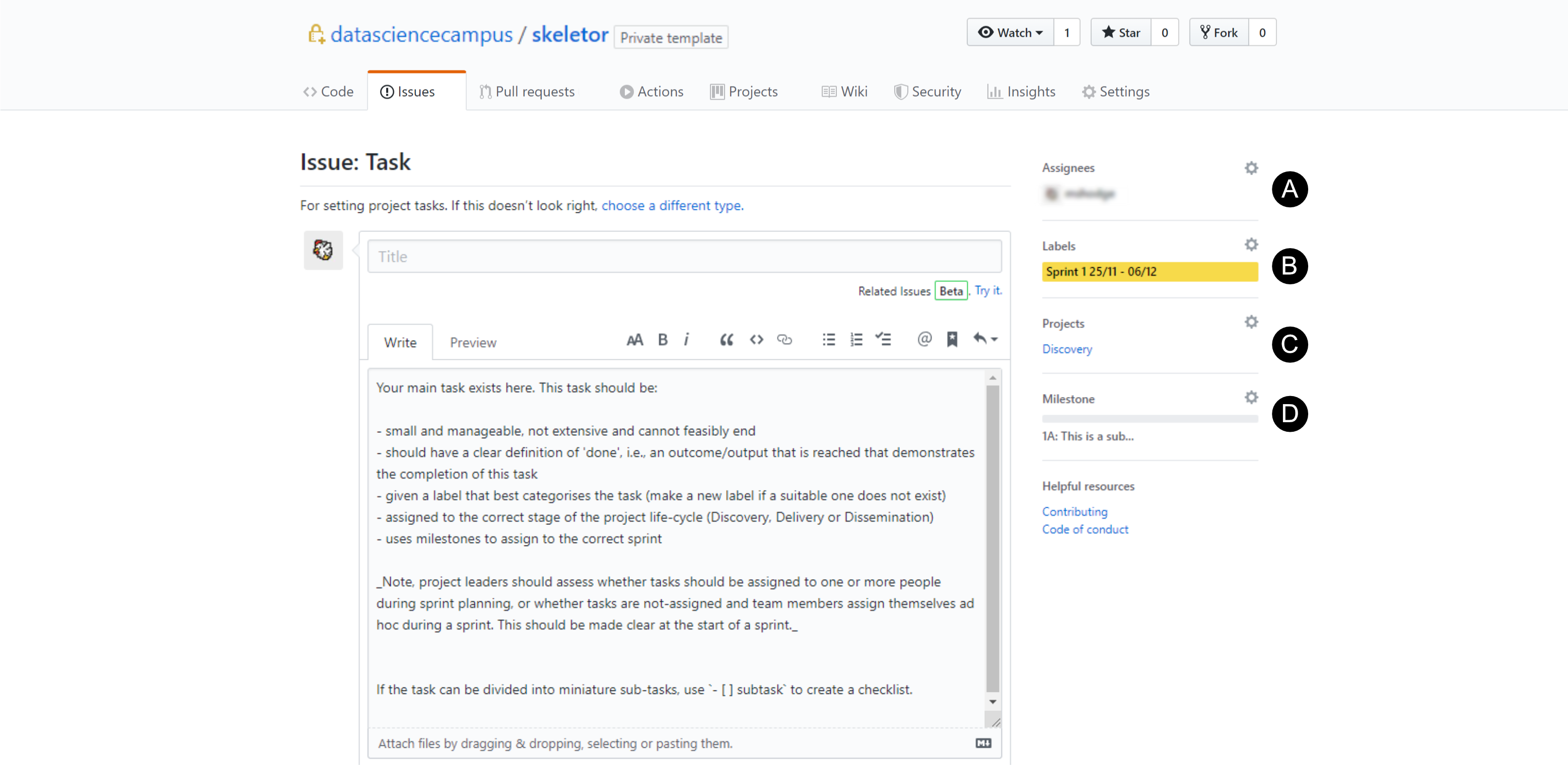 Creating an
Creating an Issue (a task) and A) assigning it to a worker, B) label with a sprint, C) adding it to the Project phase, and D) adding the Milestone it is relevant to.
Wiki
Each repository has a wiki associated to it. A wiki is just a GitHub repository. So in skeletor's repository, a template wiki with a nested structure has been created. The home page of each will contain links to pages for sprint planning, meeting notes, retrospectives, technical material etc. This allows all the information to be traced back to the home page, as this remains on top of the navigation panel on the right hand side, even when you have lots of pages.
In order to use this template, a wiki must be initiated in the project repository (create a blank home page), then the wiki can be cloned using:
git clone https://github.com/<org_name>/<repo_name>.wiki.git
By cloning both the skeletor wiki and the project repository wiki locally, the user can then overwrite the project repository’s wiki with skeletor's and push the changes back up to GitHub.
One of the problems with GitHub's wiki is the inability to drag-and-drop files into a page for upload, which is possible with GitHub Issues. The Campus’ skeletor wiki therefore contains a work-around for this by hyperlinking an Issue template, where users can use the drag-and-drop functionaility, then paste the markdown or HTML link back into their wiki page.
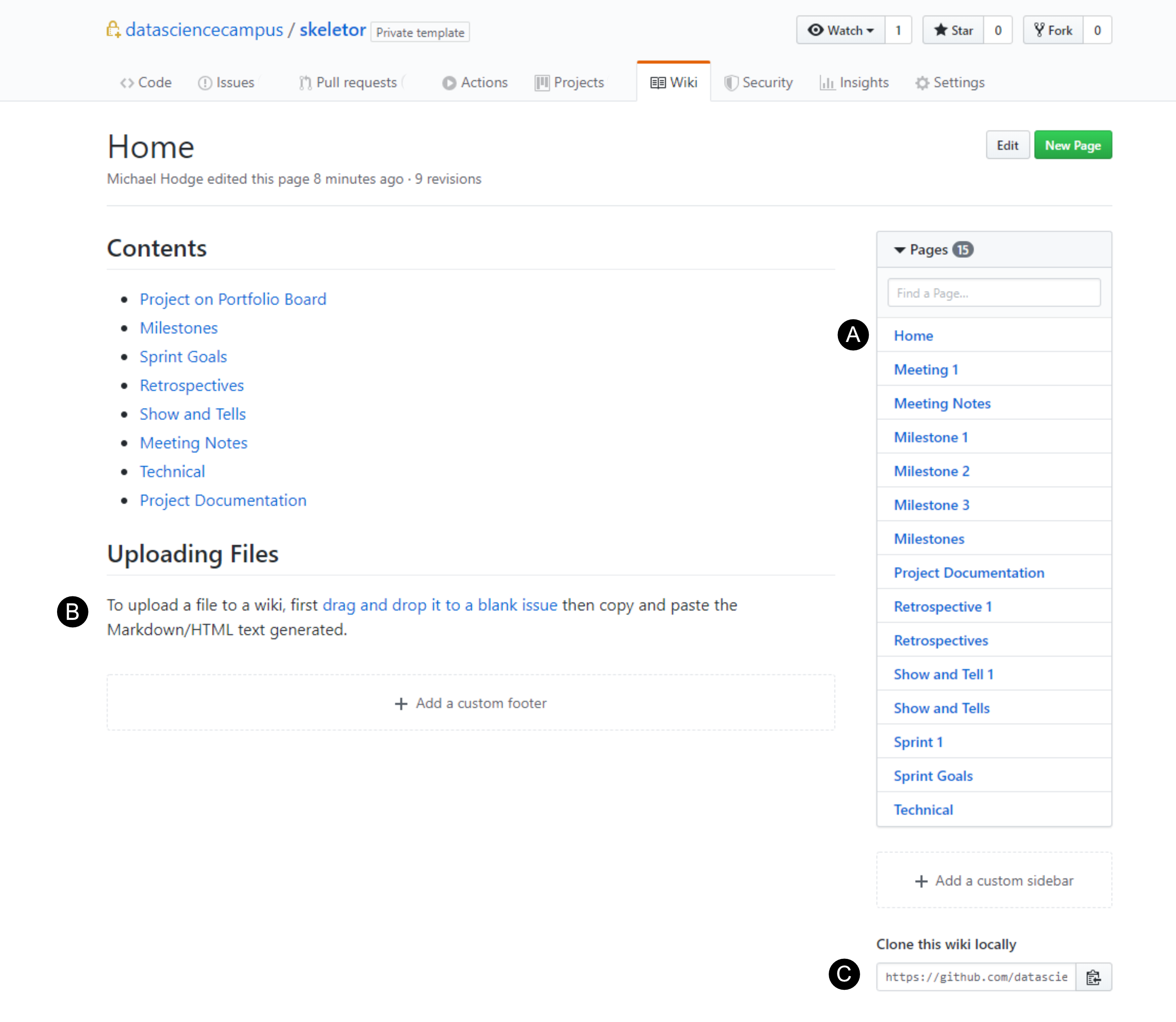 A) The Campus’
A) The Campus’ wiki template where the home page has a nested structure to various other pages. B) A workaround to uploading files to the wiki using an Issue. C) The URL of the wiki to clone it locally.
Collaborative Coding
Our project management processes above compliment a good-practice way of working in software development. Small, manageable and achievable tasks lend themselves to small, short-lived feature branches. Below describes how the Campus uses branches and source control, and why. For a more detailed look at how the Campus works, see GitFlow.
Master branch
When creating a new repository in GitHub, or when cloning from a repository template (like skeletor), GitHub will automatically create a single branched repository. This is commonly and by default called the master branch. The master branch is for clean, developed, tested, production code. In essence it contains code that will leave the building as a release.
Develop branch
To make sure any code changes don’t get pushed to the master branch before they’re ready for release, it’s best to setup a development branch to work on, called develop. Typically changes are made to this branch, and then when ready, changes on develop are pushed onto the master branch ready for release. On Campus projects, the develop branch is created straight away and made the default in the repository settings.
Feature branches
For small projects, you may rely on working solely on the develop branch. However, when working on a larger project, with more team members, coding conflicts can regularly happen if everyone is working a single branch.
One way to get around these problems is to use separate branches for each task, these are called feature branches. So that feature branches themselves do not become a hotbed for code conflicts, including rebase conflicts (where changes have been made to develop since you branched from it), feature branches should be short-lived.
This means that the reason for the branch’s creation should be small too. As said above, this fits well with an Agile way of working with small, manageable and achievable tasks. It also provides less to review before pushing to develop. If the task is a coding task, if should therefore have it’s own branch.
For best practice, the Campus adopts the following naming convention <issue num>_branch_name. This allows a trace between the branch and the task it is trying to resolve.
Commit Messages
The Campus uses the following naming convention for commits #<issue num> commit message; this will allow the commit to link to the issue on GitHub, so updates to the issue can be seen by all.
Pull Requests
When the code writen to resolve the task has been finalised it should be pushed back up to develop. To do use a Pull Request. To use a GitHub Pull Request you must assign a reviewer, who can be another team member on the project, or someone you trust to provide feedback on the code. By default the Campus has set it so that all merges back up the chain (i.e. to develop or master) require a reviewer to sign off the changes.
When making a Pull Request it is also useful to assign a sprint Label, Milestone and Project phase (like you would for the original Issue ticket). Click Create Pull Request which will send the request to the nominated reviewer.
The reviewer can accept, reject or just comment on the request. They can also provide code comments and suggested changes to the code. Once they have accepted, you can complete the Pull Request. To do this, change the Merge Pull Request option to Squash and Merge. This creates a single commit record in develop's history, unlike the default option which will push all commit messages back to develop. This may mean that several uninformative commit messages about typos will filter back into develop. For the updated commit message, write so that the first line is the headline; following lines (if needed) can give more detail as these will only be displayed when a reader clicks the ellipse.
Once the merge is complete, delete the feature branch.
Releases
Whereas the develop branch may be updated frequently with new features, the master branch should only change when a new release is ready. A Pull Request should be made to incorporate the changes from develop to master. A reviewer is then required to sign off the changes. GitHub has a release tab then that can be used to generate a release of the code repository. Details of the release should be entered. The Campus uses a vX.x.x naming convention to denote major, intermediate, and minor releases.