Method
Summary
A proof-of-concept large language model (LLM) application was created to assess whether an LLM could improve SIC autocoding performance for survey data. This was applied to sample of anonimized survey data and evaluated by comparing the results to clerical coding and to logistic regression model. The LLM showed marginal improvement over the logistic regression in the level of agreement with clerical coding at the 5-digit SIC level. It is likely that refinement of the method would improve performance further. Note that the evaluation scripts are out of scope for this repository. The methodology of the main SIC autocoding module is described bellow. For more information see Data science campus blog.
RAG based classification
The proposed LLM-based method for auto coding of free text survey responses involves two main steps. Our implementation follows the common Retrieval Augmented Generation (RAG) design, for overview see Figure 1.
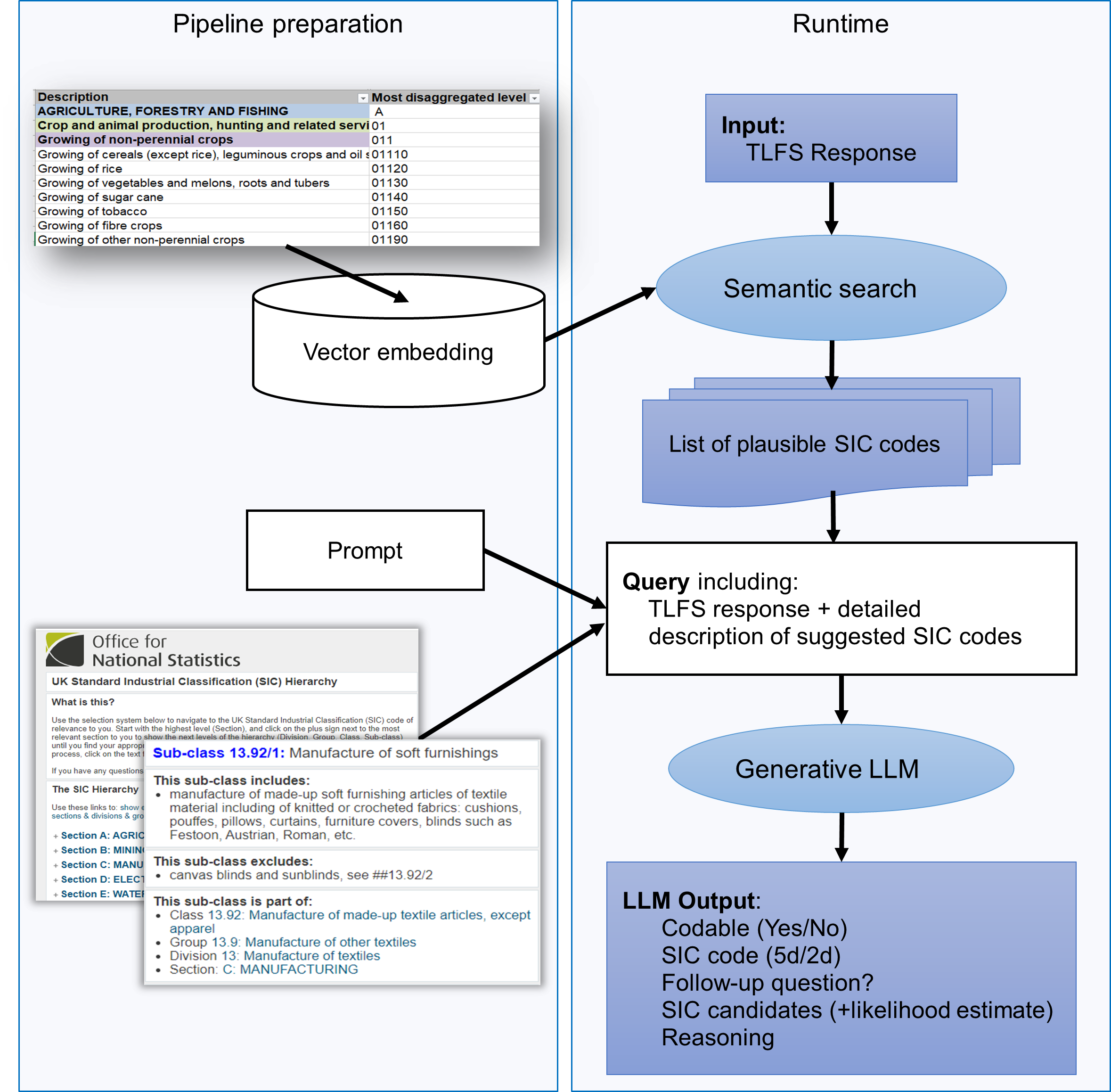
The primary input for this process consists of three free text fields from survey responses: the company’s activity, job title, and job description.
- Semantic Search of Relevant SIC Index Candidates
The first step in the process involves conducting a semantic search for relevant Standard Industrial Classification (SIC) index candidates. This is achieved by embedding of a knowledge base using transformer language model MiniLM. The knowledge base includes a list of activities, each with an assigned SIC code. MiniLM is a smaller, more efficient version of the BERT-based transformer model, designed for tasks that require understanding the semantic meaning of text. It is used to convert the text from the survey response into a form that can be compared with the embeddings of the activities in the knowledge base. The result of this step is a list of potential SIC codes that may be relevant to the response.
- LLM Query
The second step involves querying a general purpose pretrained large language model (Gemini-Pro) to evaluate which, if any, of the SIC code candidates is the best fit for the response. This step leverages the ability of LLMs to understand and generate human-like text. The LLM is presented with the response and the list of potential SIC codes and their description, and it is asked to determine which code should be assigned based on the response. If the decision cannot be confidently made the LLM is instructed to return uncodable status.
The output from the LLM is required in such a form that specific fields can be identified and easily analysed:
- Codable (Yes/No): This field indicates whether or not the survey response could be assigned a SIC code.
- SIC code: This field contains the SIC code that was determined to be the best fit for the response. The code may be requested at either the 5-digit or 2-digit levels.
- Follow-up question: This field specifies a suitable follow-up question to clarify the response in case that an appropriate SIC code cannot be readily determined.
- SIC candidates (+likelihood estimate): This field lists the SIC codes that were considered as potential matches for the response, along with an estimate of the likelihood that each code is the correct match.
- Reasoning: This field provides an explanation of why the LLM selected the particular SIC code or decided that the correct code cannot be determined.
Alterations to the pipeline were considered. For example, instead of providing a short-list of candidates one can take advantage of the ever-increasing context window (input length allowance) and include the full index or use the LLM’s own awareness of SIC index. We found these options yield worse results than the above outlined RAG for this particular task and model used.
Both steps rely on pretrained transformer-based models. Because the latest LLMs have been trained on large bodies of text and have billions of parameters they are able to identify the semantic meaning of words, nuance in grammar and spelling. In contrast with rule-based or bag-of-words based machine learning methods this improves how it handles previously unseen responses, such as emerging jobs and industries, unusually phrased or misspelled responses.
The use of pretrained models in our pipeline provides a solid foundation, but there is an option to fine-tune these models on a specific task to potentially improve performance. Fine-tuning involves continuing the training of the pretrained model on a new dataset, in this case, the survey responses and SIC codes. However, it tends to be computationally expensive and time-consuming and require large, annotated dataset, which was not available.
An alternative approach to the one-shot prompt used in the second step of the pipeline is to use an agent-based method. In this approach, instead of the LLM making a decision based on a single interaction, the LLM acts as an agent that engages in a dialogue with the text data. The LLM, acting as an agent, can be dynamically assigned different roles in the conversation or specialist tasks. However, it therefore requires more computational resources and time, as it involves multiple interactions with the LLM.
At this moment we have not evaluated the quality of provided follow-up question and reasoning but included them in the proof of concept due to their potential to improve the data collection step (whether as a one-off qualitative analysis or in real-time process).
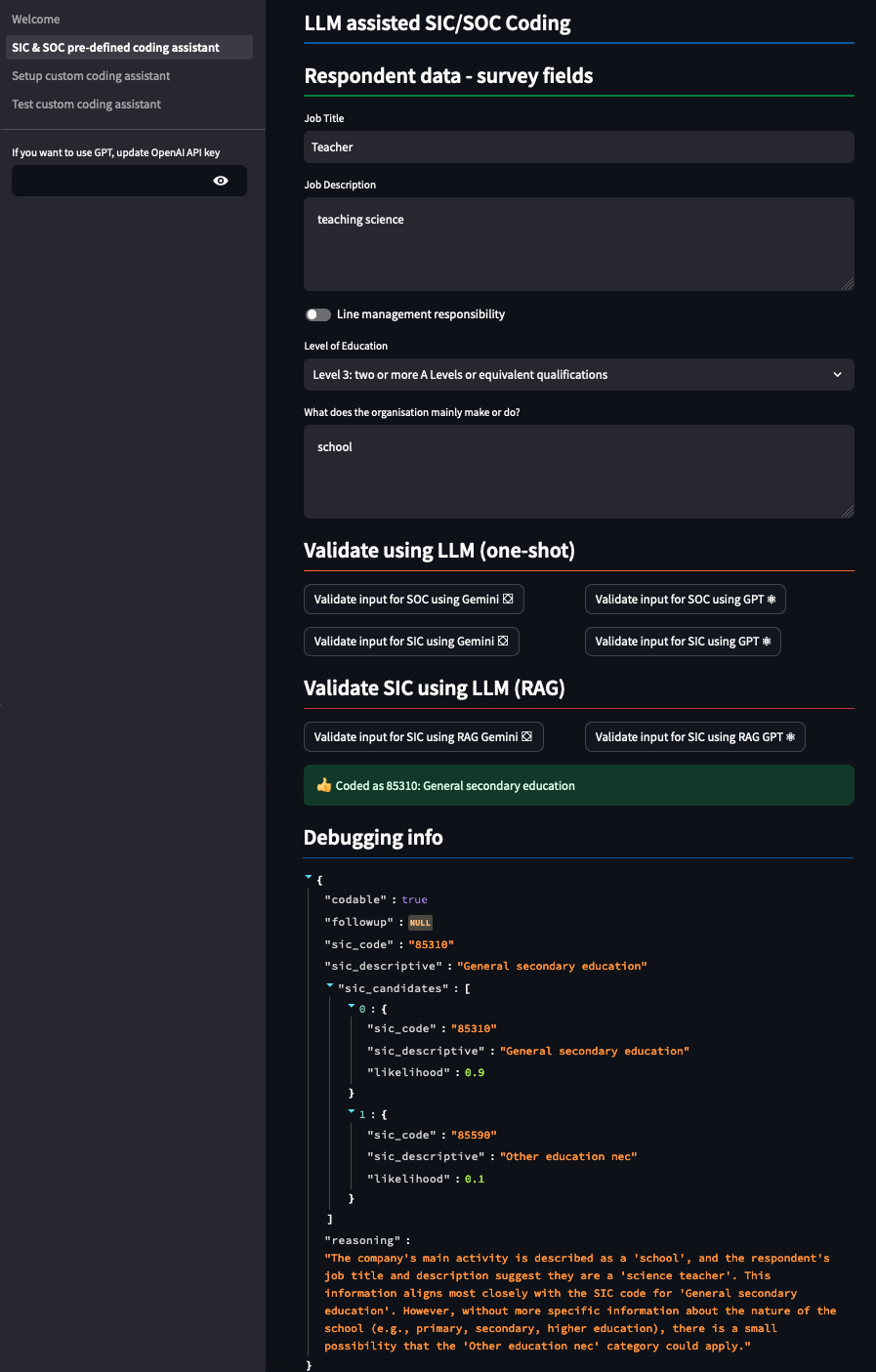
The codebase includes an example user interface. This allows small-scale testing where users can experiment with different models and test their sensitivity to the input. An example of this working with output is shown in Figure 2